
Java基本構文と制御構造 課題集 (全30問)
初級問題 (9問) 基本構文とデータ型 中級問題 (15問) 制御構造 配列と制御構造 上級問題 (6問) 解答例 初級問題の解答 int age = 25; […]
Javaプログラミングにおいて、コレクションフレームワークはデータを効率的に管理・操作するための重要なツールです。配列だけでは対応が難しい動的なデータ操作や、複雑なデータ構造が必要な場面で威力を発揮します。この記事では、特に使用頻度の高いList、Map、Setインターフェースとその主要な実装クラス(ArrayList、HashMap、HashSetなど)について詳しく解説します。
Javaのコレクションフレームワークは、主要なインターフェースとその実装クラスで構成されています。
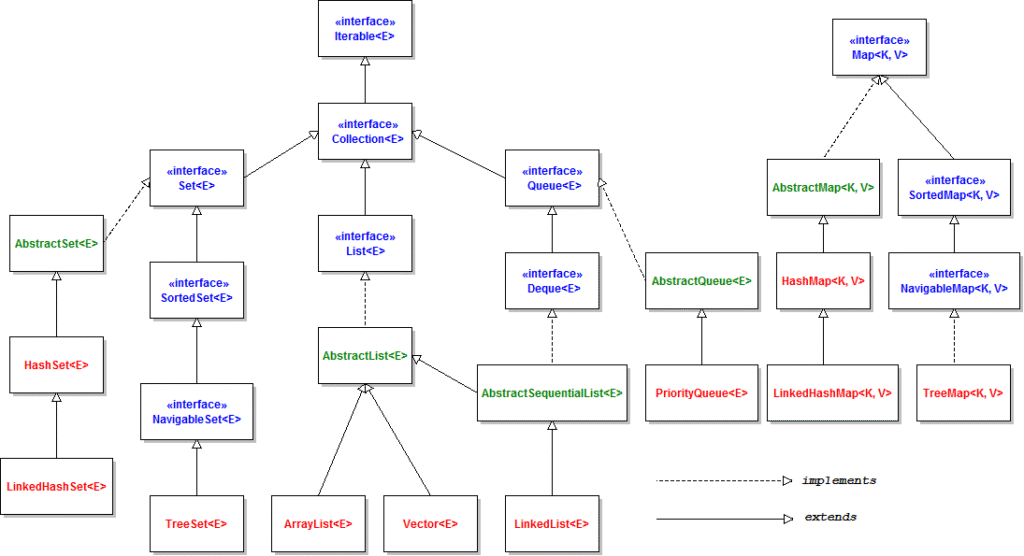
図:Javaコレクションフレームワークの階層構造(簡略版)
コレクションフレームワークを学ぶメリットは以下の通りです。
| インターフェース | 説明 | 主な実装クラス |
|---|---|---|
| List | 順序付けられた要素の集合(重複可) | ArrayList, LinkedList |
| Set | 重複を許可しない要素の集合 | HashSet, TreeSet |
| Map | キーと値のペアを管理 | HashMap, TreeMap |
| Queue | FIFO(先入れ先出し)構造 | LinkedList, PriorityQueue |
ArrayList は可変長のリストで、要素を順番に格納し、追加・取得・変更・削除などの操作を簡単に行うことができます。
プログラムでは、まず List<String> 型の fruits リストを生成し、add() メソッドで複数の果物名を追加しています(同じ要素 “Apple” の重複も可能)。get(1) で要素の取得、set() で要素の更新、remove() で要素の削除を実行し、size() でリストの要素数を出力しています。
また、拡張 for 文を使って全要素を走査し、contains() で特定の要素(”Banana”)の存在を確認しています。
import java.util.ArrayList;
import java.util.List;
public class ArrayListExample {
public static void main(String[] args) {
// ArrayListの作成
List fruits = new ArrayList<>();
// 要素の追加
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
fruits.add("Apple"); // 重複可
// 要素の取得
System.out.println(fruits.get(1)); // Banana
// 要素の変更
fruits.set(2, "Grape");
// 要素の削除
fruits.remove("Apple"); // 最初に見つかった要素を削除
// サイズの取得
System.out.println("サイズ: " + fruits.size());
// 全要素の走査
for (String fruit : fruits) {
System.out.println(fruit);
}
// 要素の存在チェック
System.out.println("Bananaを含む? " + fruits.contains("Banana"));
}
} ArrayListは内部的に配列を使用しており、以下のような特性があります。
LinkedList は、要素を双方向リンク構造で管理するリストで、要素の挿入・削除が頻繁に行われる場面に適しています。
プログラムでは、LinkedList<Integer> 型の numbers を生成し、add()・addFirst()・addLast() を使って要素を追加しています。addFirst() は先頭に、addLast() は末尾に要素を挿入します。
その後、getFirst() と getLast() で先頭と末尾の要素を取得し、removeFirst() と removeLast() でそれぞれの位置の要素を削除しています。
import java.util.LinkedList;
public class LinkedListExample {
public static void main(String[] args) {
LinkedList numbers = new LinkedList<>();
numbers.add(10);
numbers.addFirst(5); // 先頭に追加
numbers.addLast(20); // 末尾に追加
System.out.println("先頭: " + numbers.getFirst());
System.out.println("末尾: " + numbers.getLast());
numbers.removeFirst();
numbers.removeLast();
}
} | 操作 | ArrayList | LinkedList |
|---|---|---|
| 取得(get) | O(1) | O(n) |
| 追加(add) | 償却O(1) | O(1) |
| 挿入(add at index) | O(n) | O(1)(位置が既知の場合) |
| 削除(remove) | O(n) | O(1)(位置が既知の場合) |
| メモリ使用量 | 少ない(配列のみ) | 多い(ノードオブジェクト) |
使い分けのポイントは次の通りです。
ArrayListLinkedListArrayListがよく使われるHashMap は、キーと値の組み合わせをハッシュテーブルで管理するコレクションで、要素の順序は保持されず(挿入順やソート順は考慮されない)、高速な検索・追加・削除を実現します。アクセスは平均して O(1) と非常に効率的で、順序を気にせずパフォーマンスを重視する場面に適しています。
HashMap は「キー」と「値」のペアでデータを管理するコレクションで、キーを使って高速に値を検索・追加・削除できます。
プログラムでは、Map<String, Integer> 型の priceMap を作成し、put() で要素を追加しています。get() でキーに対応する値を取得し、containsKey() や containsValue() で特定のキーや値の存在を確認できます。
また、同じキーに再度 put() すると値が上書きされ、remove() でキーに対応する要素を削除します。
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// HashMapの作成
Map priceMap = new HashMap<>();
// 要素の追加
priceMap.put("Apple", 100);
priceMap.put("Banana", 80);
priceMap.put("Orange", 120);
// 要素の取得
System.out.println("Appleの価格: " + priceMap.get("Apple"));
// 要素の存在チェック
System.out.println("Mangoを含む? " + priceMap.containsKey("Mango"));
System.out.println("価格100の商品がある? " + priceMap.containsValue(100));
// 要素の上書き
priceMap.put("Apple", 110); // 既存キーの値更新
// 要素の削除
priceMap.remove("Banana");
// Mapの走査方法1: entrySet()
for (Map.Entry entry : priceMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// Mapの走査方法2: keySet()
for (String key : priceMap.keySet()) {
System.out.println(key + ": " + priceMap.get(key));
}
// Mapの走査方法3: forEach (Java 8以降)
priceMap.forEach((k, v) -> System.out.println(k + ": " + v));
}
} さらに、entrySet()・keySet()・forEach() を使った3通りの方法で Map の全要素を走査しており、これらはそれぞれ以下の通りです。
entrySet():キーと値の両方を一度に取得keySet():キーを基準に値を取り出すforEach():ラムダ式による簡潔な反復処理HashMapはハッシュテーブルをベースにした実装になります。
LinkedHashMap は、HashMap を拡張して要素の順序を保持できるコレクションであり、デフォルトでは挿入順を、設定によってはアクセス順を維持することも可能です。処理速度は HashMap よりわずかに劣るもののほぼ同等で、順序付きの出力が求められる履歴管理やキャッシュ機構などに適しています。
Map orderedMap = new LinkedHashMap<>(); TreeMap は、内部的に赤黒木(ソート木)を使用してキーを管理するコレクションで、キーが自動的に昇順(または指定した Comparator による順序)でソートされます。検索・追加・削除の処理速度は O(log n) と安定しており、キーの大小関係を利用した順序付き処理や範囲検索、ソート済みのデータ表示などに適しています。
Map sortedMap = new TreeMap<>(); HashMap は高速重視、LinkedHashMap は順序重視、TreeMap はソート重視 ― 目的に応じて使い分けるのが最適です。
| クラス名 | 順序 | 主な特徴 | 主な用途 |
|---|---|---|---|
| HashMap | なし | 高速で順序不要 | 一般的なキー・値管理 |
| LinkedHashMap | 挿入順 or アクセス順 | 順序を保持 | 順序付き出力・キャッシュ管理 |
| TreeMap | ソート順(キー基準) | 自動ソート | 並び替え・範囲検索が必要な場合 |
Set インターフェースは、重複を許さないコレクションを定義するためのインターフェースで、Java のコレクションフレームワークにおいて「集合(数学的な集合の概念)」を表します。
Set は、同じ値を複数回追加しても1つしか保持しないため要素の重複を許さず、インデックスを持たないため位置によるアクセスはできません。また、要素の順序は実装によって異なり、HashSet は順序を保持せず高速に動作し、LinkedHashSet は挿入順を維持し、TreeSet は自然順序または指定した Comparator に従ってソートされた順序で要素を管理します。
Set は、データの一意性を自動的に保証するため重複チェックの手間が不要であり、equals() と hashCode() に基づく比較によって効率的な検索・追加・削除が可能です。また、TreeSet を利用すれば要素を自動的にソートされた集合として容易に管理できます。
Set は、重複を排除したデータ管理(たとえばユーザーIDやメールアドレスの集合)や、リストから重複を除去して一意な要素を抽出する処理に利用されます。また、和・積・差といった集合演算を行うプログラムロジックの実装や、TreeSet を用いたソート済みデータの順序付き管理にも適しています。
HashSet は要素の重複を許さないデータ構造であり、要素の順序は保持しません。
プログラムでは、add() で要素を追加していますが、同じ "Alice" を2回追加しても1つしか保持されません。
また、contains() で存在確認、remove() で削除、拡張 for 文で全要素の走査を行っています。
さらに、2つの集合 uniqueNames と otherNames を用いて、
addAll() → 和集合(両方の要素をすべて含む)retainAll() → 積集合(共通する要素のみ)removeAll() → 差集合(一方にのみ存在する要素)import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
Set uniqueNames = new HashSet<>();
// 要素の追加
uniqueNames.add("Alice");
uniqueNames.add("Bob");
uniqueNames.add("Alice"); // 重複は無視
System.out.println("要素数: " + uniqueNames.size()); // 2
// 要素の存在チェック
System.out.println("Aliceを含む? " + uniqueNames.contains("Alice"));
// 要素の削除
uniqueNames.remove("Bob");
// 集合の走査
for (String name : uniqueNames) {
System.out.println(name);
}
// 他の集合操作
Set otherNames = Set.of("Alice", "Charlie");
// 和集合
Set union = new HashSet<>(uniqueNames);
union.addAll(otherNames);
// 積集合
Set intersection = new HashSet<>(uniqueNames);
intersection.retainAll(otherNames);
// 差集合
Set difference = new HashSet<>(uniqueNames);
difference.removeAll(otherNames);
}
} つまりこのコードは、HashSet を使った重複排除と集合演算の基本操作を理解する入門的なサンプルです。
HashSetは内部的にHashMapを使用しており以下の特徴があります。
HashSet は要素の重複を許さず順序を保持しない高速な集合で、検索・追加・削除が平均 O(1) の効率で行えます。
LinkedHashSet は HashSet を拡張したクラスで、要素の挿入順を保持しながら重複を排除でき、順序付き出力が可能です。
Set orderedSet = new LinkedHashSet<>(); TreeSet は要素を自動的に昇順(または指定順)にソートして保持する集合で、検索・追加・削除の処理が O(log n) で安定しています。
Set sortedSet = new TreeSet<>(); つまり、順序を気にせず高速処理したい場合は HashSet、追加順を維持したい場合は LinkedHashSet、ソート済みのデータを扱いたい場合は TreeSet を使うのが適切です。
| クラス名 | 順序の扱い | ソート | 処理速度 | 主な特徴 | 主な用途 |
|---|---|---|---|---|---|
| HashSet | 順序なし(挿入順を保持しない) | × なし | ◎ 高速(平均 O(1)) | 最もシンプルで高速な重複排除セット | 順序を気にせず、高速にデータを扱いたい場合 |
| LinkedHashSet | 挿入順を保持 | × なし | ○ やや遅い(HashSet より少し低速) | 挿入順を保ちながら重複を排除 | データを追加した順に表示したい場合(履歴・ログなど) |
| TreeSet | ソート順(自然順序または Comparator 指定順) | ○ 自動ソート | △ O(log n) | 要素を常に整列して保持 | 並び替え・範囲検索が必要な場合(辞書・ランキングなど) |
Javaのコレクションはジェネリクスを使用して型安全を実現しています。
// 非ジェネリック(古い書き方 - 非推奨)
List rawList = new ArrayList();
rawList.add("文字列");
rawList.add(10); // コンパイルは通るが危険
// ジェネリックを使用(推奨)
List stringList = new ArrayList<>();
stringList.add("文字列");
// stringList.add(10); // コンパイルエラー このコードは、Collections クラスを利用してリストの要素を昇順・降順にソートしたり、順序をランダムに並べ替えたりしたうえで、変更不可能な(イミュータブルな)リストやセットを作成する処理を示しています。
import java.util.Collections;
List numbers = new ArrayList<>();
numbers.add(5);
numbers.add(2);
numbers.add(8);
// ソート
Collections.sort(numbers);
// 逆順ソート
Collections.sort(numbers, Collections.reverseOrder());
// シャッフル
Collections.shuffle(numbers);
// 不変(immutable)なコレクション作成
List immutableList = Collections.unmodifiableList(numbers);
Set immutableSet = Collections.unmodifiableSet(new HashSet<>()); 次のコードは、List.of("A", "B", "C") で作成した不変のリストを、toArray(new String[0]) を使って 同じ内容を持つ配列に変換する処理を示しています。
List list = List.of("A", "B", "C");
String[] array = list.toArray(new String[0]); このコードは、文字列配列 array を Arrays.asList(array) で固定サイズのリストに変換し、さらにそれを new ArrayList<>(...) でラップして 要素の追加や削除が可能な可変リストを作成する処理を示しています。
String[] array = {"A", "B", "C"};
List list = Arrays.asList(array); // 固定サイズのList
List mutableList = new ArrayList<>(Arrays.asList(array)); // 可変のList fruits.stream().filter(f -> f.startsWith("A")) では、A で始まる要素のみを抽出して新しいリストを作成しています。fruits.stream().map(String::length) は、各文字列の長さを取得して整数のリストに変換します。
さらに、Collectors.groupingBy(String::length) により、文字列の長さをキーとしてグループ化した Map<Integer, List<String>> を生成します。
import java.util.stream.Collectors;
List fruits = List.of("Apple", "Banana", "Orange", "Avocado");
// フィルタリング
List aFruits = fruits.stream()
.filter(f -> f.startsWith("A"))
.collect(Collectors.toList());
// マッピング
List lengths = fruits.stream()
.map(String::length)
.collect(Collectors.toList());
// グルーピング
Map> lengthMap = fruits.stream()
.collect(Collectors.groupingBy(String::length)); つまりこのコードは、Stream API によるデータの抽出・変換・分類といった処理を宣言的に記述する方法を示した例です。
次のコードは、List.of()・Set.of()・Map.of() を使って 不変(immutable)なコレクションを作成する例です。
これらのメソッドで生成されたコレクションは要素の追加や削除、変更ができず(add() や remove() を呼ぶと UnsupportedOperationException が発生)、安全に共有できるのが特徴です。
// 不変(immutable)なコレクション作成
List immutableList = List.of("A", "B", "C");
Set immutableSet = Set.of(1, 2, 3);
Map immutableMap = Map.of("A", 1, "B", 2);
// 注意:これらのコレクションは変更不可(add/removeできない) つまりこのコードは、変更不可能なコレクションを簡潔に生成する方法を示しています。
HashSet または HashMapLinkedHashSet または LinkedHashMapTreeSet または TreeMapLinkedList(Listの場合)ArrayList(Listの場合)、HashMap(Mapの場合)大規模なコレクションを使用する場合、初期容量を設定することでリサイズのコストを削減できます。
new HashMap<>(100, 0.8f) は、初期容量 100・負荷係数(再ハッシュ化の閾値)0.8 の HashMap を生成し、大量の要素を扱う際のパフォーマンスを最適化します。new ArrayList<>(50) は、初期容量 50 の ArrayList を生成し、要素追加時の再配列コストを抑える目的があります。
// 初期容量100、負荷係数0.8のHashMap
Map largeMap = new HashMap<>(100, 0.8f);
// 初期容量50のArrayList
List largeList = new ArrayList<>(50); つまりこのコードは、初期容量と負荷係数を指定してコレクションを作成する例です。データ量を見越して効率的にコレクションを初期化する方法を示しています。
次のコードは、文字列に含まれる単語の出現回数を数える単語カウントプログラムです。
text の内容をスペースで分割し、for 文で各単語を取り出して HashMap に登録します。merge(word, 1, Integer::sum) により、同じ単語が出現した場合は既存の値に 1 を加算し、新しい単語の場合は初期値 1 を設定します(または getOrDefault() を使う方法でも同様の結果)。
最後に、forEach() で全ての単語とその出現回数を出力します。
import java.util.*;
public class WordCounter {
public static void main(String[] args) {
String text = "apple banana apple orange banana apple";
Map wordCount = new HashMap<>();
for (String word : text.split(" ")) {
wordCount.merge(word, 1, Integer::sum);
// または
// wordCount.put(word, wordCount.getOrDefault(word, 0) + 1);
}
wordCount.forEach((word, count) ->
System.out.println(word + ": " + count));
}
} つまりこのコードは、Map を活用してデータの集計(頻度カウント)を簡潔に行う方法を示した例です。
studentGrades は、学生名をキー、複数の成績(整数のリスト)を値として保持する HashMap です。addGrade() メソッドでは、computeIfAbsent() を使って存在しない学生のエントリを自動生成し、成績を追加します。
getAverage() メソッドは、指定された学生の平均点を Stream API で計算します。getTopStudents() メソッドでは、全学生を平均点の降順でソートし、上位 n 名の学生名を LinkedHashSet に収集します(順序を保持)。
import java.util.*;
public class GradeManager {
private Map> studentGrades = new HashMap<>();
public void addGrade(String studentName, int grade) {
studentGrades.computeIfAbsent(studentName, k -> new ArrayList<>()).add(grade);
}
public double getAverage(String studentName) {
List grades = studentGrades.get(studentName);
if (grades == null || grades.isEmpty()) return 0;
return grades.stream()
.mapToInt(Integer::intValue)
.average()
.orElse(0);
}
public Set getTopStudents(int n) {
return studentGrades.entrySet().stream()
.sorted(Comparator.comparingDouble(
e -> -getAverage(e.getKey()))) // 降順ソート
.limit(n)
.map(Map.Entry::getKey)
.collect(Collectors.toCollection(LinkedHashSet::new));
}
} つまりこのコードは、Map と Stream を組み合わせてデータの蓄積・集計・ランキングを効率的に行う実践的なオブジェクト指向設計の例です。
次のコードは、ArrayList を拡張 for 文(拡張 for ループ)で走査中に要素を削除しようとしている例で、**ConcurrentModificationException(同時変更例外)**が発生します。
for-each 構文は内部的に Iterator を使ってリストを走査しますが、ループ中に直接 list.remove() を呼び出すと、Iterator が管理しているコレクションの状態と実際のリストの状態が不一致になるため例外がスローされます。
List list = new ArrayList<>(List.of("A", "B", "C"));
for (String s : list) {
if (s.equals("B")) {
list.remove(s); // ConcurrentModificationException
}
} この問題を回避するには、以下のように**Iterator の remove() メソッド**を使って安全に削除します。
Java のコレクション(特に HashSet や HashMap)は、要素の等価性を判定する際に equals() と hashCode() の両方を使用します。
そのため、equals() だけをオーバーライドすると、論理的には同じオブジェクトでも異なるハッシュ値を持つ可能性があり、重複して格納されたり、検索できなくなったりする不具合が発生します。
class Person {
String name;
// equalsをオーバーライドしたがhashCodeをオーバーライドしない
// → HashSetやHashMapで問題が発生
}つまりこのコードは、equals() をオーバーライドした場合は、常に hashCode() も整合性の取れるようにオーバーライドすべきことを示しています。
HashMap は、キーの検索や格納に hashCode() と equals() の結果を使います。しかし、キーとして使用したリスト key に add("b") で要素を追加すると、その内容が変化して hashCode() の値も変わり、マップが保持しているハッシュ構造と整合しなくなります。
その結果、map.get(key) で値を取得しようとしても見つからないなど、**マップの整合性が壊れる(実質的にキーが消えたように見える)**という問題が発生します。
Map, String> map = new HashMap<>();
List key = new ArrayList<>();
key.add("a");
map.put(key, "value");
key.add("b"); // キーが変更されたため、マップが壊れる つまりこのコードは、HashMap のキーには変更されない(不変)オブジェクトを使うべきという重要な原則を示しています。
List<String> list = new ArrayList<>(); のようにインターフェース型で宣言すると、後で LinkedList や CopyOnWriteArrayList など 異なる実装クラスに容易に変更できる柔軟性があります。
一方、ArrayList<String> list = new ArrayList<>(); と具体的なクラス型で宣言すると、実装を変更する際にコード全体の修正が必要になり、拡張性や保守性が下がるというデメリットがあります。
List list = new ArrayList<>(); // 良い
ArrayList list = new ArrayList<>(); // 悪くはないが柔軟性に欠ける つまりこのコードは、コレクションの宣言には実装クラスではなくインターフェース型を使うのが望ましいという設計上のベストプラクティスを示しています。
このコードは、Collections.unmodifiableList() を使って 既存の可変リスト(mutableList)を変更不可能なリストにラップする例です。
これにより、immutable から要素の追加・削除・変更を行おうとすると UnsupportedOperationException が発生しますが、元の mutableList を直接変更すれば内容は反映されます。
List immutable = Collections.unmodifiableList(mutableList); つまりこのコードは、リストの外部からの変更を防ぎ、安全にデータを共有するための不変ビューを作成する方法を示しています。
ArrayListは内部的に配列で要素を管理しており、容量が不足すると自動的に新しい配列を確保してデータをコピーします。
そのため、あらかじめ要素数を見積もって初期容量を指定しておくと、再配列(リサイズ)によるコストを削減し、メモリ効率とパフォーマンスを向上させることができます。
new ArrayList<>(1000); // 約1000要素が予想される場合つまりこのコードは、大量の要素を追加することが予想される場合に最適化されたArrayListの初期化方法を示しています。
次のコードは、Map において キーが存在しない場合に自動的に新しいリストを作成し、そのリストに値を追加する処理を1行で行う書き方です。
computeIfAbsent(key, k -> new ArrayList<>()) は、指定した key が map に存在しなければ新しい ArrayList を作成して登録し、存在する場合は既存のリストを返します。
その結果、後続の .add(value) で安全に値を追加できます。
map.computeIfAbsent(key, k -> new ArrayList<>()).add(value);つまりこのコードは、キーごとにリストなどのコレクションを管理するマルチマップ的な構造を簡潔に実装する方法を示しています。
この記事では、Javaのコレクションフレームワークの中核であるList、Map、Setについて詳しく解説しました。重要なポイントをまとめます。
List – 順序付けられた要素の集合(重複可)、ArrayListとLinkedListが主要実装Map – キーと値のペアを管理、HashMapが最も一般的Set – 重複を許可しない要素の集合、HashSetが基本実装コレクションフレームワークはJavaプログラミングの基盤です。実際のプロジェクトで積極的に活用し、その便利さと強力さを実感してください。最初はシンプルな使い方から始め、徐々に高度な機能を習得していくのがおすすめです。
以下のプログラムを完成させ、実行結果が以下のようになるようにしてください。
実行結果:
リストの内容: [Apple, Banana, Orange]
要素数: 3
2番目の要素: Banana
Orangeはリストに含まれています: true
更新後のリスト: [Apple, Grape, Orange, Mango]import java.util.ArrayList;
import java.util.List;
public class ListBasic {
public static void main(String[] args) {
// 1. ArrayListを作成し、"Apple", "Banana", "Orange"を追加
// 2. リストの内容を表示
// 3. 要素数を表示
// 4. 2番目の要素を表示(インデックスは0から始まる)
// 5. "Orange"がリストに含まれているかチェック
// 6. "Banana"を"Grape"に置き換え
// 7. 最後に"Mango"を追加
// 8. 更新後のリストを表示
}
}以下のプログラムを完成させ、実行結果が以下のようになるようにしてください。
実行結果:
学生データ:
101: 山田太郎
102: 佐藤花子
103: 鈴木一郎
102番の学生: 佐藤花子
104番の学生は存在しますか: false
更新後の学生データ:
101: 山田太郎
102: 佐藤優子
103: 鈴木一郎
104: 田中次郎import java.util.HashMap;
import java.util.Map;
public class MapBasic {
public static void main(String[] args) {
// 1. HashMapを作成(キー: Integer, 値: String)
// 2. 学生データを追加(101:山田太郎, 102:佐藤花子, 103:鈴木一郎)
// 3. すべての学生データを表示
// 4. 102番の学生を検索して表示
// 5. 104番の学生が存在するかチェック
// 6. 102番の学生を"佐藤優子"に更新
// 7. 104番の学生"田中次郎"を追加
// 8. 更新後の学生データを表示
}
}以下のプログラムを完成させ、実行結果が以下のようになるようにしてください。
実行結果:
セットの内容: [Apple, Banana, Orange]
要素数: 3
Bananaはセットに含まれています: true
重複追加の結果: false
更新後のセット: [Apple, Banana, Grape, Orange]
Grapeを削除: true
最終的なセット: [Apple, Banana, Orange]import java.util.HashSet;
import java.util.Set;
public class SetBasic {
public static void main(String[] args) {
// 1. HashSetを作成
// 2. "Apple", "Banana", "Orange"を追加
// 3. セットの内容を表示(順序は保証されない)
// 4. 要素数を表示
// 5. "Banana"がセットに含まれているかチェック
// 6. "Apple"を重複して追加し、結果を表示
// 7. "Grape"を追加
// 8. 更新後のセットを表示
// 9. "Grape"を削除し、結果を表示
// 10. 最終的なセットを表示
}
}整数のリストから以下の処理を行うプログラムを作成してください。
実行結果:
すべての要素: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
偶数のみ: 2 4 6 8 10
5より大きい要素を削除後: [1, 2, 3, 4, 5]以下の処理を行うプログラムを作成してください。
ランダムな整数を生成してArrayListに追加し、重複をSetを使ってチェックするプログラムを作成してください。
学生の成績管理システムを作成してください。
Studentクラス(name, score)を作成してください。
以下の処理を行うプログラムを作成してください。
以下の要件を満たす在庫管理システムを作成してください。
投票結果を集計するシステムを作成ください。
図書館の貸出管理システムを作成してください。
import java.util.ArrayList;
import java.util.List;
public class ListBasic {
public static void main(String[] args) {
// 1. ArrayListを作成し、"Apple", "Banana", "Orange"を追加
List fruits = new ArrayList<>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 2. リストの内容を表示
System.out.println("リストの内容: " + fruits);
// 3. 要素数を表示
System.out.println("要素数: " + fruits.size());
// 4. 2番目の要素を表示(インデックスは0から始まる)
System.out.println("2番目の要素: " + fruits.get(1));
// 5. "Orange"がリストに含まれているかチェック
System.out.println("Orangeはリストに含まれています: " + fruits.contains("Orange"));
// 6. "Banana"を"Grape"に置き換え
fruits.set(1, "Grape");
// 7. 最後に"Mango"を追加
fruits.add("Mango");
// 8. 更新後のリストを表示
System.out.println("更新後のリスト: " + fruits);
}
} import java.util.HashMap;
import java.util.Map;
public class MapBasic {
public static void main(String[] args) {
// 1. HashMapを作成(キー: Integer, 値: String)
Map students = new HashMap<>();
// 2. 学生データを追加(101:山田太郎, 102:佐藤花子, 103:鈴木一郎)
students.put(101, "山田太郎");
students.put(102, "佐藤花子");
students.put(103, "鈴木一郎");
// 3. すべての学生データを表示
System.out.println("学生データ:");
for (Map.Entry entry : students.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 4. 102番の学生を検索して表示
System.out.println("102番の学生: " + students.get(102));
// 5. 104番の学生が存在するかチェック
System.out.println("104番の学生は存在しますか: " + students.containsKey(104));
// 6. 102番の学生を"佐藤優子"に更新
students.put(102, "佐藤優子");
// 7. 104番の学生"田中次郎"を追加
students.put(104, "田中次郎");
// 8. 更新後の学生データを表示
System.out.println("更新後の学生データ:");
for (Map.Entry entry : students.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
} import java.util.HashSet;
import java.util.Set;
public class SetBasic {
public static void main(String[] args) {
// 1. HashSetを作成
Set fruits = new HashSet<>();
// 2. "Apple", "Banana", "Orange"を追加
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Orange");
// 3. セットの内容を表示(順序は保証されない)
System.out.println("セットの内容: " + fruits);
// 4. 要素数を表示
System.out.println("要素数: " + fruits.size());
// 5. "Banana"がセットに含まれているかチェック
System.out.println("Bananaはセットに含まれています: " + fruits.contains("Banana"));
// 6. "Apple"を重複して追加し、結果を表示
System.out.println("重複追加の結果: " + fruits.add("Apple"));
// 7. "Grape"を追加
fruits.add("Grape");
// 8. 更新後のセットを表示
System.out.println("更新後のセット: " + fruits);
// 9. "Grape"を削除し、結果を表示
System.out.println("Grapeを削除: " + fruits.remove("Grape"));
// 10. 最終的なセットを表示
System.out.println("最終的なセット: " + fruits);
}
} import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListIntermediate {
public static void main(String[] args) {
// 1. 1から10までの整数を含むArrayListを作成
List numbers = new ArrayList<>();
for (int i = 1; i <= 10; i++) {
numbers.add(i);
}
// 2. forループを使用してすべての要素を表示
System.out.println("すべての要素: " + numbers);
// 3. 拡張forループを使用して偶数のみを表示
System.out.print("偶数のみ: ");
for (int num : numbers) {
if (num % 2 == 0) {
System.out.print(num + " ");
}
}
System.out.println();
// 4. 5より大きい要素をすべて削除(Iteratorを使用)
Iterator iterator = numbers.iterator();
while (iterator.hasNext()) {
if (iterator.next() > 5) {
iterator.remove();
}
}
// 5. 処理後のリストを表示
System.out.println("5より大きい要素を削除後: " + numbers);
}
} import java.util.HashMap;
import java.util.Map;
public class MapIntermediate {
public static void main(String[] args) {
// 1. 商品名をキー、価格を値とするHashMapを作成
Map products = new HashMap<>();
// 2. 商品を追加
products.put("りんご", 100);
products.put("バナナ", 80);
products.put("オレンジ", 120);
products.put("メロン", 500);
// 3. すべての商品と価格を表示
System.out.println("すべての商品:");
for (Map.Entry entry : products.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue() + "円");
}
// 4. 価格が100円以上の商品のみを表示
System.out.println("\n100円以上の商品:");
for (Map.Entry entry : products.entrySet()) {
if (entry.getValue() >= 100) {
System.out.println(entry.getKey() + ": " + entry.getValue() + "円");
}
}
// 5. すべての商品の価格を10%値上げ
for (Map.Entry entry : products.entrySet()) {
int newPrice = (int)(entry.getValue() * 1.1);
products.put(entry.getKey(), newPrice);
}
// 6. 値上げ後の商品と価格を表示
System.out.println("\n値上げ後の商品:");
for (Map.Entry entry : products.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue() + "円");
}
}
} import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Random;
import java.util.Set;
public class SetIntermediate {
public static void main(String[] args) {
Random random = new Random();
List numbers = new ArrayList<>();
// 1. 1から10の範囲で20個のランダムな整数をArrayListに追加
for (int i = 0; i < 20; i++) {
numbers.add(random.nextInt(10) + 1);
}
// 2. 元のリストと重複の数を表示
System.out.println("元のリスト: " + numbers);
System.out.println("元のリストの要素数: " + numbers.size());
// HashSetを使って重複を除去
Set uniqueNumbers = new HashSet<>(numbers);
System.out.println("重複除去後の要素数: " + uniqueNumbers.size());
System.out.println("重複の数: " + (numbers.size() - uniqueNumbers.size()));
// 3. 重複除去後のリストを表示
List uniqueList = new ArrayList<>(uniqueNumbers);
System.out.println("重複除去後のリスト: " + uniqueList);
}
} import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class GradeManagement {
public static void main(String[] args) {
// 1. 学生の名前とテストの点数を管理するMapを作成
Map> studentGrades = new HashMap<>();
// サンプルデータを追加
studentGrades.put("山田太郎", new ArrayList<>(List.of(85, 90, 78)));
studentGrades.put("佐藤花子", new ArrayList<>(List.of(92, 88, 95)));
studentGrades.put("鈴木一郎", new ArrayList<>(List.of(76, 82, 79)));
// 2. 各学生の平均点、最高点、最低点を計算して表示
for (Map.Entry> entry : studentGrades.entrySet()) {
String studentName = entry.getKey();
List grades = entry.getValue();
double average = calculateAverage(grades);
int max = findMax(grades);
int min = findMin(grades);
System.out.println(studentName + ":");
System.out.println(" 点数: " + grades);
System.out.println(" 平均点: " + String.format("%.2f", average));
System.out.println(" 最高点: " + max);
System.out.println(" 最低点: " + min);
System.out.println();
}
}
private static double calculateAverage(List grades) {
int sum = 0;
for (int grade : grades) {
sum += grade;
}
return (double) sum / grades.size();
}
private static int findMax(List grades) {
int max = Integer.MIN_VALUE;
for (int grade : grades) {
if (grade > max) {
max = grade;
}
}
return max;
}
private static int findMin(List grades) {
int min = Integer.MAX_VALUE;
for (int grade : grades) {
if (grade < min) {
min = grade;
}
}
return min;
}
} import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
class Student {
String name;
int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
@Override
public String toString() {
return name + ":" + score;
}
}
public class StudentManagement {
public static void main(String[] args) {
// 1. Studentオブジェクトを複数作成してArrayListに追加
List students = new ArrayList<>();
students.add(new Student("山田", 85));
students.add(new Student("佐藤", 92));
students.add(new Student("鈴木", 76));
students.add(new Student("田中", 88));
students.add(new Student("高橋", 65));
System.out.println("元のリスト: " + students);
// 2. 点数でソートして表示
Collections.sort(students, new Comparator() {
@Override
public int compare(Student s1, Student s2) {
return Integer.compare(s2.score, s1.score); // 降順
}
});
System.out.println("点数順(降順): " + students);
// 3. 点数が80点以上の学生のみを抽出して表示
System.out.print("80点以上の学生: ");
for (Student student : students) {
if (student.score >= 80) {
System.out.print(student + " ");
}
}
}
} import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class CollectionConversion {
public static void main(String[] args) {
// 1. 文字列のListを作成
List originalList = new ArrayList<>();
originalList.add("apple");
originalList.add("banana");
originalList.add("apple");
originalList.add("orange");
originalList.add("banana");
originalList.add("grape");
System.out.println("元のList: " + originalList);
// 2. ListをSetに変換して重複を除去
Set setFromList = new HashSet<>(originalList);
System.out.println("Setに変換(重複除去): " + setFromList);
// 3. Setを再度Listに変換
List listFromSet = new ArrayList<>(setFromList);
System.out.println("再びListに変換: " + listFromSet);
// 各段階の要素数を表示
System.out.println("\n要素数の変化:");
System.out.println("元のList: " + originalList.size() + "要素");
System.out.println("Set: " + setFromList.size() + "要素");
System.out.println("変換後のList: " + listFromSet.size() + "要素");
}
} import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class Product {
private String code;
private String name;
private int stock;
private double price;
public Product(String code, String name, int stock, double price) {
this.code = code;
this.name = name;
this.stock = stock;
this.price = price;
}
// ゲッターとセッター
public String getCode() { return code; }
public String getName() { return name; }
public int getStock() { return stock; }
public double getPrice() { return price; }
public void setStock(int stock) { this.stock = stock; }
public void setPrice(double price) { this.price = price; }
@Override
public String toString() {
return String.format("商品コード: %s, 商品名: %s, 在庫: %d, 価格: %.2f円",
code, name, stock, price);
}
}
class InventoryManager {
private Map products;
public InventoryManager() {
products = new HashMap<>();
}
// 商品追加
public void addProduct(Product product) {
products.put(product.getCode(), product);
System.out.println("商品を追加しました: " + product.getName());
}
// 商品削除
public boolean removeProduct(String code) {
Product removed = products.remove(code);
if (removed != null) {
System.out.println("商品を削除しました: " + removed.getName());
return true;
}
System.out.println("商品が見つかりません: " + code);
return false;
}
// 商品検索
public Product findProduct(String code) {
return products.get(code);
}
// 在庫更新
public boolean updateStock(String code, int newStock) {
Product product = products.get(code);
if (product != null) {
product.setStock(newStock);
System.out.println("在庫を更新しました: " + product.getName() + " -> " + newStock);
return true;
}
return false;
}
// 在庫切れ商品のリストを取得
public List getOutOfStockProducts() {
List outOfStock = new ArrayList<>();
for (Product product : products.values()) {
if (product.getStock() == 0) {
outOfStock.add(product);
}
}
return outOfStock;
}
// 価格帯で商品を検索
public List findProductsByPriceRange(double minPrice, double maxPrice) {
List result = new ArrayList<>();
for (Product product : products.values()) {
if (product.getPrice() >= minPrice && product.getPrice() <= maxPrice) {
result.add(product);
}
}
return result;
}
// すべての商品を表示
public void displayAllProducts() {
System.out.println("=== すべての商品 ===");
for (Product product : products.values()) {
System.out.println(product);
}
}
}
public class InventorySystem {
public static void main(String[] args) {
InventoryManager manager = new InventoryManager();
// 商品を追加
manager.addProduct(new Product("P001", "ノートパソコン", 10, 120000));
manager.addProduct(new Product("P002", "マウス", 0, 2500));
manager.addProduct(new Product("P003", "キーボード", 5, 5000));
manager.addProduct(new Product("P004", "モニター", 3, 30000));
manager.addProduct(new Product("P005", "USBケーブル", 0, 800));
System.out.println();
// すべての商品を表示
manager.displayAllProducts();
System.out.println();
// 在庫切れ商品を表示
System.out.println("=== 在庫切れ商品 ===");
List outOfStock = manager.getOutOfStockProducts();
for (Product product : outOfStock) {
System.out.println(product);
}
System.out.println();
// 価格帯で検索
System.out.println("=== 1,000円〜5,000円の商品 ===");
List priceRangeProducts = manager.findProductsByPriceRange(1000, 5000);
for (Product product : priceRangeProducts) {
System.out.println(product);
}
System.out.println();
// 商品検索
System.out.println("=== 商品検索 ===");
Product found = manager.findProduct("P003");
if (found != null) {
System.out.println("検索結果: " + found);
}
// 在庫更新
manager.updateStock("P002", 15);
}
} import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class VotingSystem {
public static void main(String[] args) {
// 1. 候補者名のリスト(投票結果)
List votes = new ArrayList<>();
votes.add("山田太郎");
votes.add("佐藤花子");
votes.add("山田太郎");
votes.add("鈴木一郎");
votes.add("佐藤花子");
votes.add("山田太郎");
votes.add("田中次郎");
votes.add("佐藤花子");
votes.add("山田太郎");
votes.add("鈴木一郎");
// 2. Mapを使って候補者名と得票数を集計
Map voteCount = new HashMap<>();
for (String candidate : votes) {
voteCount.put(candidate, voteCount.getOrDefault(candidate, 0) + 1);
}
// 3. 得票数でソートしてランキングを表示
List> sortedEntries = new ArrayList<>(voteCount.entrySet());
Collections.sort(sortedEntries, new Comparator>() {
@Override
public int compare(Map.Entry e1, Map.Entry e2) {
return e2.getValue().compareTo(e1.getValue()); // 降順
}
});
// ソート結果をLinkedHashMapに格納(順序保持)
Map sortedResults = new LinkedHashMap<>();
for (Map.Entry entry : sortedEntries) {
sortedResults.put(entry.getKey(), entry.getValue());
}
// ランキング表示
System.out.println("=== 投票結果ランキング ===");
int rank = 1;
for (Map.Entry entry : sortedResults.entrySet()) {
System.out.println(rank + "位: " + entry.getKey() + " - " + entry.getValue() + "票");
rank++;
}
// 4. 最多得票者とその得票数を表示
Map.Entry topCandidate = sortedEntries.get(0);
System.out.println("\n最多得票者: " + topCandidate.getKey() + " (" + topCandidate.getValue() + "票)");
// 総投票数
int totalVotes = votes.size();
System.out.println("総投票数: " + totalVotes + "票");
// 得票率の計算と表示
System.out.println("\n=== 得票率 ===");
for (Map.Entry entry : sortedResults.entrySet()) {
double percentage = (double) entry.getValue() / totalVotes * 100;
System.out.printf("%s: %.1f%% (%d票)%n",
entry.getKey(), percentage, entry.getValue());
}
}
} import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
class Book {
private String isbn;
private String title;
private String author;
private boolean isBorrowed;
public Book(String isbn, String title, String author) {
this.isbn = isbn;
this.title = title;
this.author = author;
this.isBorrowed = false;
}
// ゲッター
public String getIsbn() { return isbn; }
public String getTitle() { return title; }
public String getAuthor() { return author; }
public boolean isBorrowed() { return isBorrowed; }
// セッター
public void setBorrowed(boolean borrowed) { this.isBorrowed = borrowed; }
@Override
public String toString() {
String status = isBorrowed ? "貸出中" : "貸出可能";
return String.format("ISBN: %s, タイトル: %s, 著者: %s, 状態: %s",
isbn, title, author, status);
}
}
class Member {
private String memberId;
private String name;
private List borrowedBooks;
public Member(String memberId, String name) {
this.memberId = memberId;
this.name = name;
this.borrowedBooks = new ArrayList<>();
}
// ゲッター
public String getMemberId() { return memberId; }
public String getName() { return name; }
public List getBorrowedBooks() { return borrowedBooks; }
// 本を借りる
public boolean borrowBook(Book book) {
if (borrowedBooks.size() < 5) { // 最大5冊まで
borrowedBooks.add(book);
return true;
}
return false;
}
// 本を返す
public boolean returnBook(Book book) {
return borrowedBooks.remove(book);
}
@Override
public String toString() {
return String.format("会員ID: %s, 名前: %s, 貸出冊数: %d",
memberId, name, borrowedBooks.size());
}
}
class Library {
private Map books; // ISBNで検索
private Map members; // 会員IDで検索
public Library() {
books = new HashMap<>();
members = new HashMap<>();
}
// 本を登録
public void addBook(Book book) {
books.put(book.getIsbn(), book);
System.out.println("本を登録しました: " + book.getTitle());
}
// 会員を登録
public void addMember(Member member) {
members.put(member.getMemberId(), member);
System.out.println("会員を登録しました: " + member.getName());
}
// 本を貸し出す
public boolean borrowBook(String memberId, String isbn) {
Member member = members.get(memberId);
Book book = books.get(isbn);
if (member == null) {
System.out.println("会員が見つかりません: " + memberId);
return false;
}
if (book == null) {
System.out.println("本が見つかりません: " + isbn);
return false;
}
if (book.isBorrowed()) {
System.out.println("この本は既に貸出中です: " + book.getTitle());
return false;
}
if (member.borrowBook(book)) {
book.setBorrowed(true);
System.out.println("貸出完了: " + member.getName() + "が「" + book.getTitle() + "」を借りました");
return true;
} else {
System.out.println("貸出制限を超えています(最大5冊まで)");
return false;
}
}
// 本を返却
public boolean returnBook(String memberId, String isbn) {
Member member = members.get(memberId);
Book book = books.get(isbn);
if (member == null || book == null) {
System.out.println("会員または本が見つかりません");
return false;
}
if (member.returnBook(book)) {
book.setBorrowed(false);
System.out.println("返却完了: " + member.getName() + "が「" + book.getTitle() + "」を返却しました");
return true;
} else {
System.out.println("この会員は指定された本を借りていません");
return false;
}
}
// 本を検索
public Book findBook(String isbn) {
return books.get(isbn);
}
// 会員を検索
public Member findMember(String memberId) {
return members.get(memberId);
}
// 利用可能な本のリストを表示
public void displayAvailableBooks() {
System.out.println("=== 利用可能な本 ===");
for (Book book : books.values()) {
if (!book.isBorrowed()) {
System.out.println(book);
}
}
}
// すべての会員と貸出状況を表示
public void displayAllMembers() {
System.out.println("=== すべての会員 ===");
for (Member member : members.values()) {
System.out.println(member);
if (!member.getBorrowedBooks().isEmpty()) {
System.out.println(" 貸出中の本:");
for (Book book : member.getBorrowedBooks()) {
System.out.println(" - " + book.getTitle());
}
}
}
}
}
public class LibrarySystem {
public static void main(String[] args) {
Library library = new Library();
// 本を登録
library.addBook(new Book("ISBN001", "Java入門", "山田太郎"));
library.addBook(new Book("ISBN002", "デザインパターン", "佐藤花子"));
library.addBook(new Book("ISBN003", "アルゴリズム", "鈴木一郎"));
library.addBook(new Book("ISBN004", "データベース", "田中次郎"));
// 会員を登録
library.addMember(new Member("M001", "高橋優"));
library.addMember(new Member("M002", "中村美咲"));
System.out.println();
// 本の貸出
library.borrowBook("M001", "ISBN001");
library.borrowBook("M001", "ISBN002");
library.borrowBook("M002", "ISBN003");
System.out.println();
// 利用可能な本を表示
library.displayAvailableBooks();
System.out.println();
// すべての会員を表示
library.displayAllMembers();
System.out.println();
// 本の返却
library.returnBook("M001", "ISBN001");
System.out.println();
// 返却後の状況を表示
library.displayAvailableBooks();
}
}