
変数とデータ型(let, const, プリミティブ型)
はじめに JavaScriptを学ぶ上で、変数とデータ型の理解は基礎中の基礎です。この知識なしでは効果的なプログラミングはできません。現代のJavaScript […]
前章で学んだ非同期処理の基礎を踏まえて、今回はその具体的な実装方法の1つである「コールバック関数」について詳しく解説します。
コールバック関数はJavaScriptの非同期処理において長年使われてきた基本的なパターンであり、Promiseやasync/awaitを理解する上でも重要な基礎知識です。
この概念をしっかり理解することで、より高度な非同期処理もスムーズに学べるようになります。
コールバック関数(Callback Function)とは、他の関数に引数として渡され、特定のタイミングや条件が満たされたときに「呼び出される(call back)」関数のことです。
英語の”call back”(折り返し電話する、後で呼び返す)という表現が由来です。
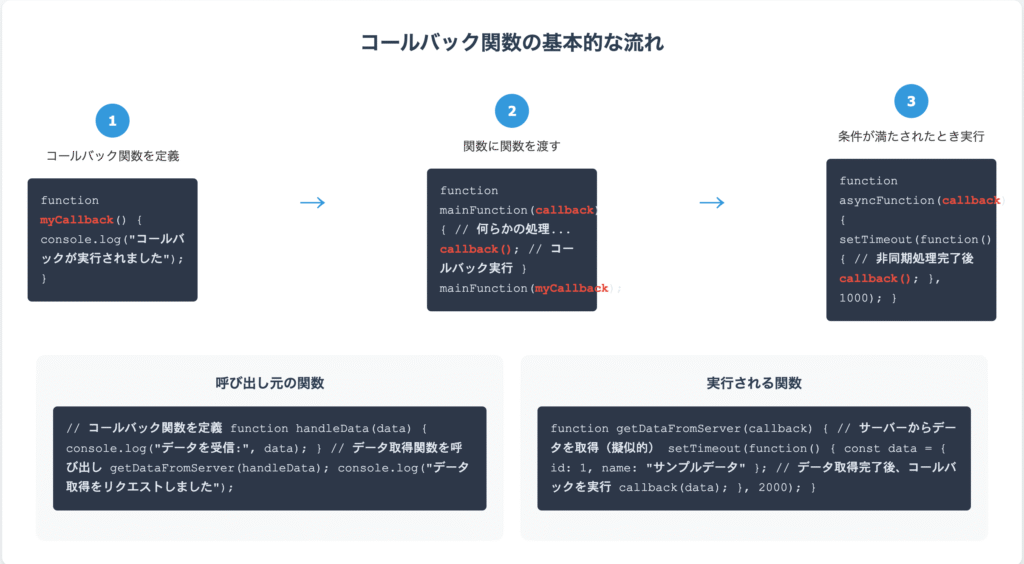
まずは同期処理におけるコールバックの例を見てみましょう。
function greet(name, callback) {
console.log(`こんにちは、${name}さん!`);
callback(); // コールバック関数の実行
}
function sayGoodbye() {
console.log("さようなら!");
}
greet("太郎", sayGoodbye);
// 実行結果
// こんにちは、太郎さん!
// さようなら!この例では、sayGoodbye関数がコールバック関数としてgreet関数に渡され、greet関数内で実行されています。
コールバック関数が真価を発揮するのは非同期処理の場合です。
function fetchData(callback) {
setTimeout(() => {
console.log("データ取得完了");
callback("取得したデータ");
}, 1000);
}
function processData(data) {
console.log(`処理中のデータ: ${data}`);
}
fetchData(processData);
console.log("データ取得を開始します");
// データ取得を開始します
// (1秒後)
// データ取得完了
// 処理中のデータ: 取得したデータこの例では、fetchData関数が非同期処理(setTimeout)を行います。setTimeout処理は1秒間(1000ms)実行されます。その処理が完了した時点でコールバック関数processDataを呼び出しています。
これにより処理が完了するときにはprocessData処理の取得したデータをコールバックして表示させる仕組みになります。
JavaScript、特にブラウザ環境では、以下のような非同期処理が頻繁に発生します。
setTimeout, setInterval)これらの処理は完了までに時間がかかるため、コールバック関数を使って「処理が終わったらこの関数を実行して」と指示する必要があります。
Node.jsで広く使われているパターンで、コールバック関数の第一引数をエラーオブジェクト、第二引数以降を処理結果とする方式です。
function asyncOperation(input, callback) {
// 何らかの非同期処理
if (errorOccurred) {
callback(new Error("何か問題が発生しました"));
} else {
callback(null, result);
}
}
asyncOperation("someInput", function(err, result) {
if (err) {
console.error(err);
return;
}
console.log("結果:", result);
});このパターンの利点は以下の通りです。
一見便利そうなコールバック関数ですが、問題もあります。その代表的なものにコールバック地獄という表現があります。
コールバック関数を多用すると、ネストが深くなり、コードの可読性や保守性が著しく低下する現象です。例えば次のようなコードを見てください。
getUserData(function(user) {
getFriendsList(user.id, function(friends) {
getPosts(friends[0].id, function(posts) {
getComments(posts[0].id, function(comments) {
console.log(comments);
});
});
});
});このようなコードは以下の問題を引き起こします。
このコールバックの深さは関数を複雑にし、可読性を下げるため不向きとされています。そのため、このような処理を実装する場合には以下のような工夫を行う必要があります。
関数分割の例を以下に示します。この例では以下のステップになっています。
function handleComments(comments) {
console.log(comments);
}
function handlePosts(posts) {
getComments(posts[0].id, handleComments);
}
function handleFriends(friends) {
getPosts(friends[0].id, handlePosts);
}
function handleUser(user) {
getFriendsList(user.id, handleFriends);
}
getUserData(handleUser);ステップ1: getUserData()でユーザーデータを取得
ステップ2: 取得したユーザーIDでgetFriendsList()を実行
ステップ3: 最初の友達IDでgetPosts()を実行
ステップ4: 最初の投稿IDでgetComments()を実行
ステップ5: 最終的にコメントデータをconsole.logで出力
このように、各関数の完了を待って次の関数を実行するコールバック地獄の構造になっています。
1. コールバック地獄(Callback Hell)
深くネストしたコールバックにより、コードが読みにくく、保守困難になります。
2. エラーハンドリングの難しさ
各コールバックで個別にエラー処理が必要で、統一的なエラーハンドリングが困難です。
3. 制御フローの複雑さ
並行処理や順次実行の制御が難しく、コードの見通しが悪くなります。
これらの問題を解決するために、Promiseやasync/awaitが導入されました。
ユーザーのクリックなどの操作を検知し、指定した関数を実行します。
インタラクティブなWebサイトの実現に不可欠です。
document.getElementById("myButton").addEventListener("click", function() {
console.log("ボタンがクリックされました");
});この例では、匿名関数がコールバックとして渡され、ボタンがクリックされた時に実行されます。
指定した時間が経過した後に処理を実行します。
アニメーションの制御や遅延実行など、時間管理に使用されます。
setTimeout(function() {
console.log("3秒が経過しました");
}, 3000);ファイルの読み込みが完了したらコールバック関数を実行します。
非同期で効率的なファイル操作を実現します。
const fs = require('fs');
fs.readFile('example.txt', 'utf8', function(err, data) {
if (err) {
console.error("エラーが発生しました:", err);
return;
}
console.log("ファイル内容:", data);
});コールバック関数のベストプラクティスは、「エラーファーストコールバック」の徹底、適切なネスト管理による「コールバック地獄」の回避、可能な限りPromiseやasync/awaitへの移行、そしてコールバックの再利用性とテスト容易性を高める観点でまとめられます。これにより保守性と可読性が向上します。
複数の非同期処理を順番に実行する例を見てみましょう。
function asyncTask1(callback) {
setTimeout(() => {
console.log("タスク1完了");
callback(null, "結果1");
}, 1000);
}
function asyncTask2(data, callback) {
setTimeout(() => {
console.log(`タスク2完了。前の結果: ${data}`);
callback(null, "結果2");
}, 1000);
}
function asyncTask3(data, callback) {
setTimeout(() => {
console.log(`タスク3完了。前の結果: ${data}`);
callback(null, "結果3");
}, 1000);
}
// 実行シーケンス
asyncTask1((err, result1) => {
if (err) {
console.error(err);
return;
}
asyncTask2(result1, (err, result2) => {
if (err) {
console.error(err);
return;
}
asyncTask3(result2, (err, result3) => {
if (err) {
console.error(err);
return;
}
console.log("最終結果:", result3);
});
});
});この例では、3つの非同期タスクを順番に実行し、前のタスクの結果を次のタスクに渡しています。
すでにネストが深くなり始めていることがわかります。
コールバック関数には前述のような問題があるため、JavaScriptの進化と共に新しいパターンが導入されました。
次の章では、コールバック関数の問題点を解決するPromiseについて学びますが、その前にコールバック関数の概念をしっかり理解しておくことが重要です。
コールバック関数はJavaScriptの非同期処理の基礎として長年使われてきました。
特にNode.jsの初期バージョンでは、非同期I/Oを実現する主要な方法でした。
しかし、すでに説明したような問題から、現代ではPromiseやasync/awaitが推奨されるようになりました。とはいえ、多くの既存のライブラリやコードベースでコールバック関数が使われているため、理解しておくことは重要です。
コールバック関数は、他の関数に渡されて特定のタイミングで実行される仕組みで、JavaScriptの非同期処理を支える基本的な方法です。
イベント処理やタイマー、ネットワークリクエストなどで多く使われ、Node.jsではエラーファーストパターンが一般的に採用されています。
ただし、ネストが深くなると「コールバック地獄」と呼ばれる可読性の低下が問題となるため、現在はPromiseやasync/awaitが推奨されますが、既存のコードでは依然として広く利用されており、非同期処理を理解するうえで欠かせない概念です。
コールバック関数はJavaScriptプログラミングの基本的な要素であり、多くのライブラリやフレームワークでも使用されています。この概念をしっかり理解することで、より複雑な非同期処理も理解できるようになります。
理解を深めるための問題を用意しました。
以下のコードの実行結果を予想してください。
console.log("開始");
function delayedLog(message, callback) {
setTimeout(() => {
console.log(message);
callback();
}, 1000);
}
delayedLog("1秒後", () => {
delayedLog("さらに1秒後", () => {
console.log("終了");
});
});次のコールバック関数の特徴について、正しいものには○、間違っているものには×をつけてください。
以下のコードをエラーファーストコールバックパターンを使って書き直してください。
function calculate(a, b, operation, callback) {
let result;
if (operation === 'add') {
result = a + b;
} else if (operation === 'subtract') {
result = a - b;
} else {
callback("未知の演算です");
return;
}
callback(result);
}開始
(1秒後)1秒後
(さらに1秒後)さらに1秒後
終了理由:
console.log("開始") が同期的に実行される。1秒後 を出力し、その後コールバックでさらに setTimeout をセット。さらに1秒後 が出力され、続いて 終了 が同期的に実行される。コールバック関数は同期処理でのみ使用できる (×)
エラーファーストコールバックパターンでは、エラーがなければ第一引数にnullを渡す (○)
コールバック地獄とは、コールバック関数のネストが深くなりすぎる問題を指す (○)
すべてのコールバック関数は非同期で実行される (×)
理由:
Array.map は同期的)。(error, result) 形式が基本で、エラーなしなら null を渡す。function calculate(a, b, operation, callback) {
let result;
if (operation === 'add') {
result = a + b;
} else if (operation === 'subtract') {
result = a - b;
} else {
// エラーの場合は第一引数にエラーを渡す
callback(new Error("未知の演算です"), null);
return;
}
// エラーなしなら第一引数はnull、結果は第二引数
callback(null, result);
}
// 使用例
calculate(5, 3, 'add', (err, result) => {
if (err) {
console.error("エラー:", err.message);
} else {
console.log("結果:", result);
}
});